Redis Cluster (集群)
青云QingCloud Redis 集群提供原生的开源 Redis 3.x,除了继续支持以前的一主多从外,还支持多主多从,每个主所在分片 (shard) 平均分摊 16384 个 slots, 增加或删除主节点系统会自动平衡 slots (因为需要迁移数据,时间会有点长)。并且集群支持 HA, 即当某个主节点异常,它的从节点会自动切换成主节点。
创建
在本例中,我们将介绍如何创建一个具有多主多从架构的 Redis 集群缓存服务。
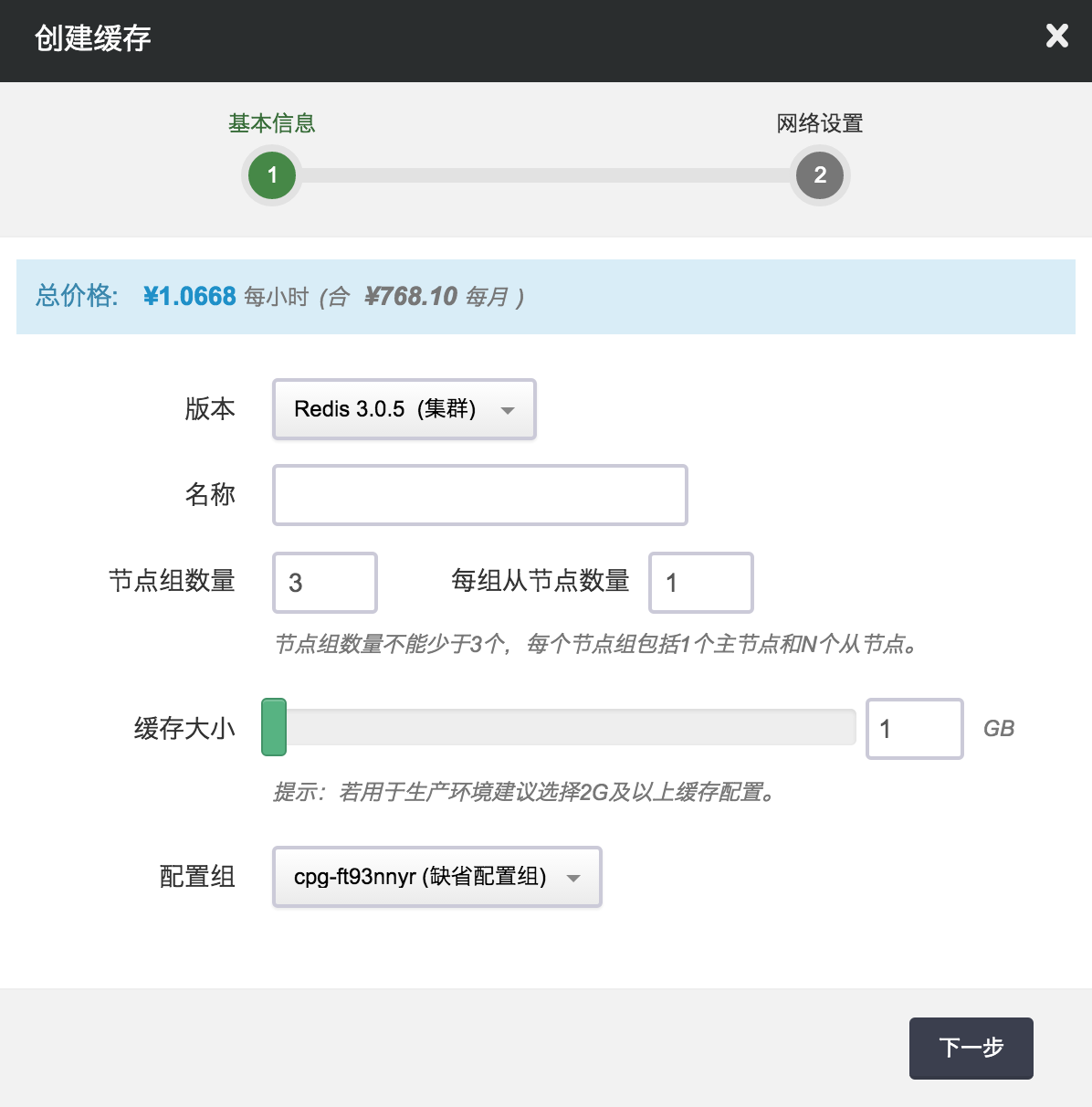
第一步:选择基本配置
在创建的对话框中,您需要指定缓存服务的类型为 Redis3.0.5(集群)。 每个 Redis 集群服务都会包含至少 3 个节点组, 每个节点组包括 N 个从节点(replicate, 即每个节点组的从节点个数, 可以是 0 个)。 默认情况下,指定 3 个节点组, 每组 1 个从节点,即这个 Redis 集群缓存服务将创建 6 个节点,选择每个节点的缓存大小及配置组,然后点击提交。
注解 主节点是可读可写的,而从节点是只读的。
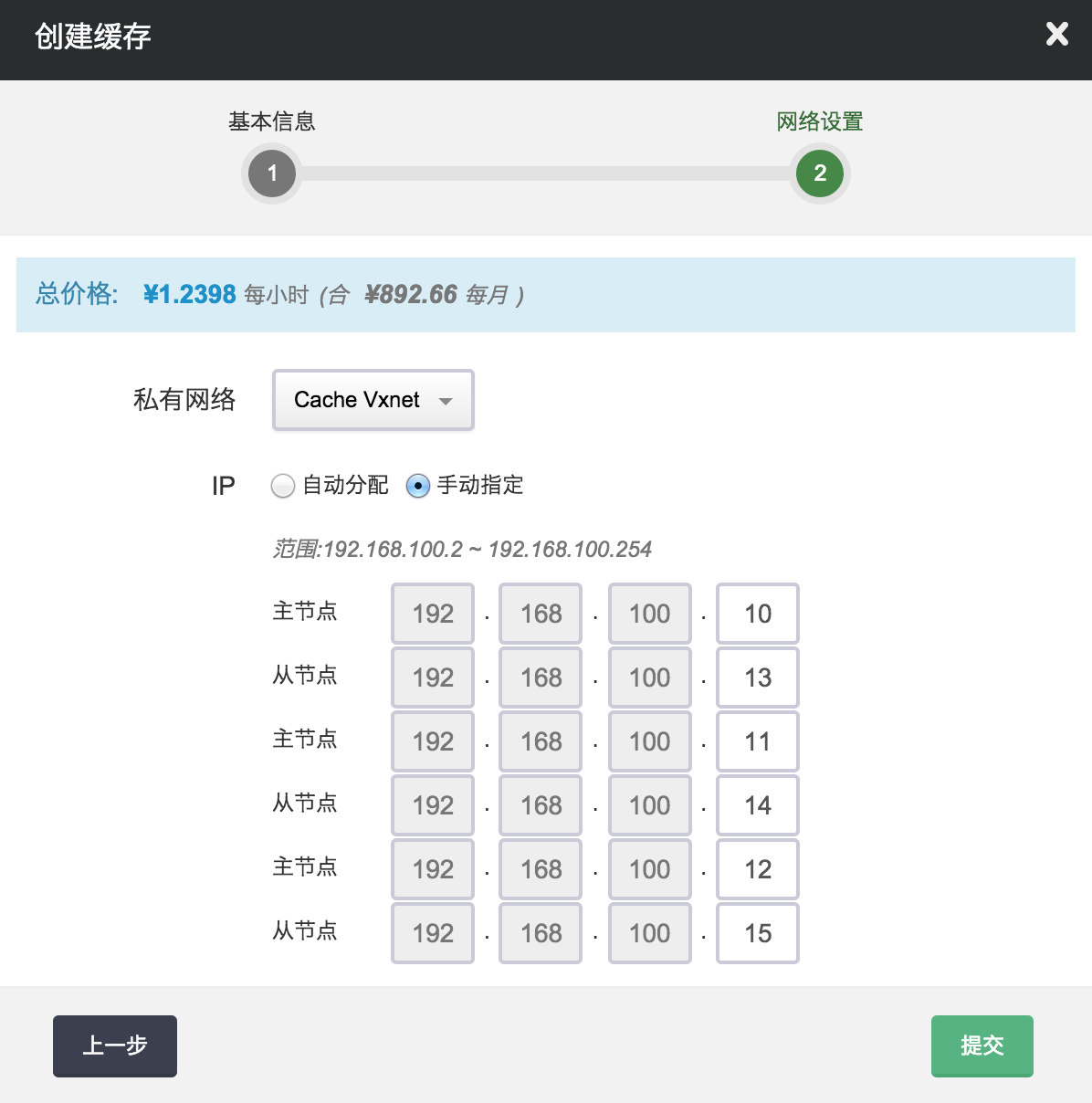
第二步:配置网络
在配置网络的过程中,我们首先需要选择缓存服务要加入的私有网络。 然后我们可以为缓存服务中的每个节点指定 IP,例如我们指定 主节点的 IP 为 192.168.100.10,192.168.100.11,192.168.100.12,从节点的 IP 为 192.168.100.13,192.168.100.14,192.168.100.15。 您也可以选择”自动分配”,让系统自动指定 IP。
第三步:创建成功
当缓存服务创建完成之后,我们可以查看缓存节点的运行状态。 如图所示,缓存节点的 IP 为我们指定的 IP 地址,同时为 “活跃” 状态,表示各缓存节点连接正常。

测试
当缓存服务创建完成之后,我们可以进行连接测试。
1)检查集群状态
在同一私网中创建一台 Linux 主机,您可能需要先装一些依赖包 (如Ubuntu下apt-get install tcl ruby 和 gem install redis), 然后请 下载 Redis 3.x, 解压后进入 Redis src目录,执行以下命令 (假设 Redis cluster 其中一个节点的 IP 为 192.168.100.13, 端口为 6379)。
./redis-trib.rb check 192.168.100.13:6379
然后您能看到如下的集群信息
Connecting to node 192.168.100.13:6379: OK
Connecting to node 192.168.100.11:6379: OK
Connecting to node 192.168.100.10:6379: OK
Connecting to node 192.168.100.14:6379: OK
Connecting to node 192.168.100.12:6379: OK
Connecting to node 192.168.100.15:6379: OK
Performing Cluster Check (using node 192.168.100.13:6379)
S: f6092dbdb25b6d80416232e50ccd2022860086b0 192.168.100.13:6379
slots: (0 slots) slave
replicates b2d75900b6427f6fbf8ec1a61ee301a2c8f73a6d
M: d3377079e01391b9d16ea699c79453e15f5aa132 192.168.100.11:6379
slots:0-5460 (5461 slots) master
1 additional replica(s)
M: b2d75900b6427f6fbf8ec1a61ee301a2c8f73a6d 192.168.100.10:6379
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 9774f5ff6477eaecb6794395ed726d0f06257c60 192.168.100.14:6379
slots: (0 slots) slave
replicates d3377079e01391b9d16ea699c79453e15f5aa132
M: 704514eb7fa135dd003533568ae9f7babda9464e 192.168.100.12:6379
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 22b3f49a6b87403faeeb1219881e63096802eb6a 192.168.100.15:6379
slots: (0 slots) slave
replicates 704514eb7fa135dd003533568ae9f7babda9464e
[OK] All nodes agree about slots configuration.
Check for open slots...
Check slots coverage...
[OK] All 16384 slots covered.
如果发现集群出现异常,比如出现 [ERR] Nodes don’t agree about configuration! 可以尝试用如下命令修复
./redis-trib.rb fix 192.168.100.13:6379
如果发现各分片的 slots 分配不平均,也可以用如下命令平衡一下 (从两个分片迁移 1000 个 slots 到第三个分片里)
./redis-trib.rb reshard --from d3377079e01391b9d16ea699c79453e15f5aa132,b2d75900b6427f6fbf8ec1a61ee301a2c8f73a6d
--to 704514eb7fa135dd003533568ae9f7babda9464e --slots 1000 --yes 192.168.100.13:6379
2)Java 客户端读写数据示例
首先 下载 Jedis 库和 Apache Commons Pool 依赖库。 把下载下来的 commons-pool2-2.0.jar 和 jedis-2.7.3.jar 放到同一目录下如 lib/, 创建 TestRedisCluster.java,内容如下。 然后编译、执行该 Java 程序(假设一个分片的主从节点分别是 192.168.100.10, 192.168.100.13, 端口均为 6379)。
javac -cp :./lib/* TestRedisCluster.java
java -cp :./lib/* TestRedisCluster 192.168.100.10, 192.168.100.13 6379
import java.util.Set;
import java.util.HashSet;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.HostAndPort;
public class TestRedisCluster {
public static void main(String[] args) {
Set jedisClusterNodes = new HashSet();
//Jedis Cluster will attempt to discover cluster nodes automatically
jedisClusterNodes.add(new HostAndPort(args[0], Integer.valueOf(args[2])));
jedisClusterNodes.add(new HostAndPort(args[1], Integer.valueOf(args[2])));
JedisCluster jc = new JedisCluster(jedisClusterNodes);
String str = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890";
int len = str.length();
int loop = 0;
while (loop
注解 这是示例代码,不承担任何责任。更多的 Redis 客户端请见 Redis 官方网站。
3) Hash Tags Keys
Redis 集群采用 CRC16 算法对 key 值哈希到 16384 个 slots 中的一个,因此不同的 key 可能分散到不同的节点中,对于想固定一类 key 值到某一个节点,如按业务分类,可以采用 Hash Tags,下面是从 Redis 文档 摘录的解释。
In order to implement hash tags, the hash slot is computed in a different way. Basically if the key contains a “{…}” pattern only the substring between { and } is hashed in order to obtain the hash slot. However since it is possible that there are multiple occurrences of { or } the algorithm is well specified by the following rules:
- If the key contains a { character
- There is a } character on the right of {
- There are one or more characters between the first occurrence of { and the first occurrence of } after the first occurrence of {.
Then instead of hashing the key, only what is between the first occurrence of { and the first occurrence of } on its right are hashed.
Examples:
- The two keys {user1000}.following and {user1000}.followers will hash to the same hash slot since only the substring user1000 will be hashed in order to compute the hash slot.
- For the key foo{}{bar} the whole key will be hashed as usually since the first occurrence of { is followed by } on the right without characters in the middle.
- For the key foozap the substring {bar will be hashed, because it is the substring between the first occurrence of { and the first occurrence of } on its right.
- For the key foo{bar}{zap} the substring bar will be hashed, since the algorithm stops at the first valid or invalid (without bytes inside) match of { and }.
- What follows from the algorithm is that if the key starts with {}, it is guaranteed to be hashes as a whole. This is useful when using binary data as key names.
在线伸缩
在缓存服务运行过程中,会出现服务能力不足或者容量不够的情况,可以通过扩容来解决,或者服务能力过剩时可以删除节点。在纵向扩容中, 服务需要重启,所以这个时候业务需要停止。在横向伸缩中,数据会发生迁移,但并不影响业务的正常运行。
1)增加集群分片 (shard)
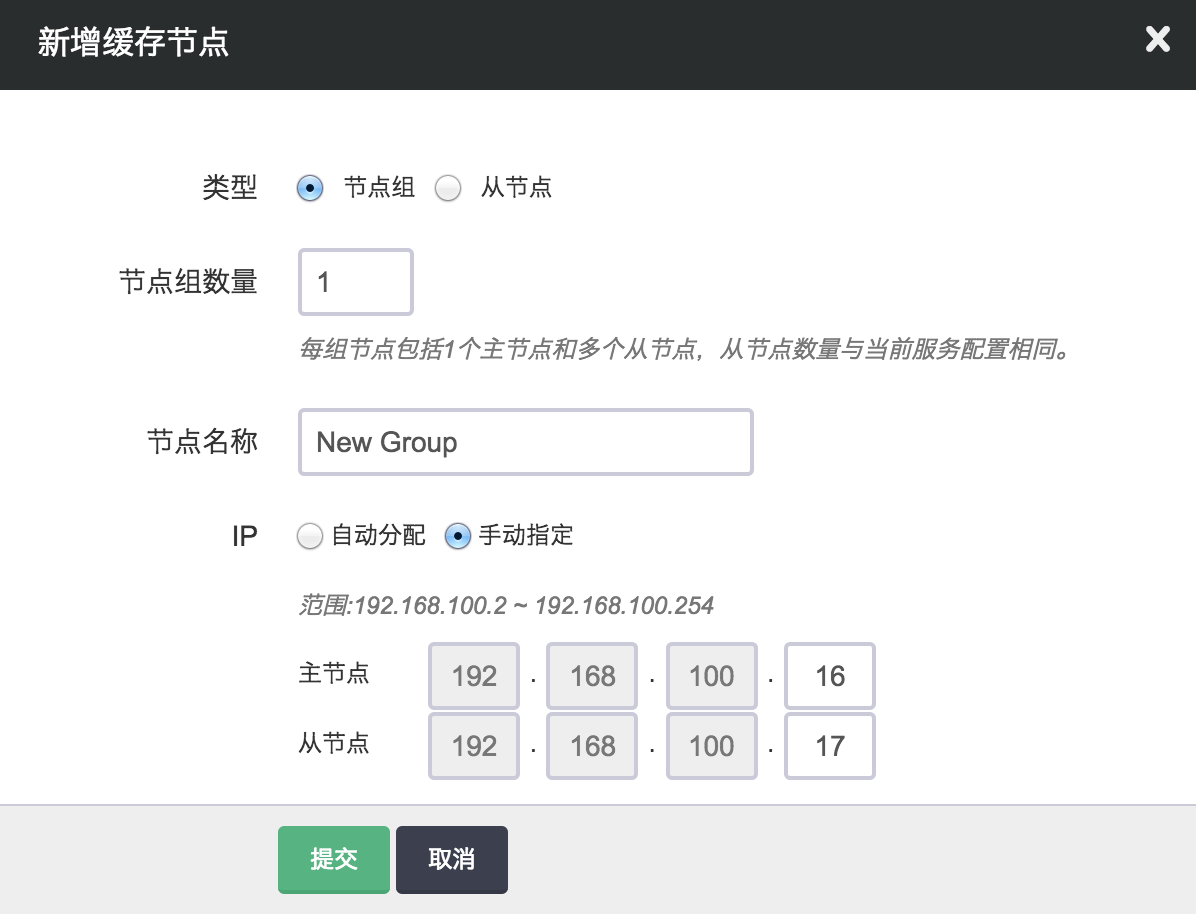
Redis 集群服务每个主节点写的能力与容量都有上限,当写的能力不满足业务需求或达到容量上限时,您可以通过增加节点组即缓存分片来提升写性能以及容量。 每增加一个节点组时将创建一个主节点和其它主节点同样的从节点数。青云QingCloud Redis 集群服务会自动平衡各分片之间的 slots,即会发生 数据迁移,因此增加节点组的时间会有点长。如果事先知道需要增加的分片数建议一次性完成,这样比一次只加一个分片效率更高。 如图所示,我们在原有集群基础上新增一个节点组,并在创建时为新节点指定 IP。
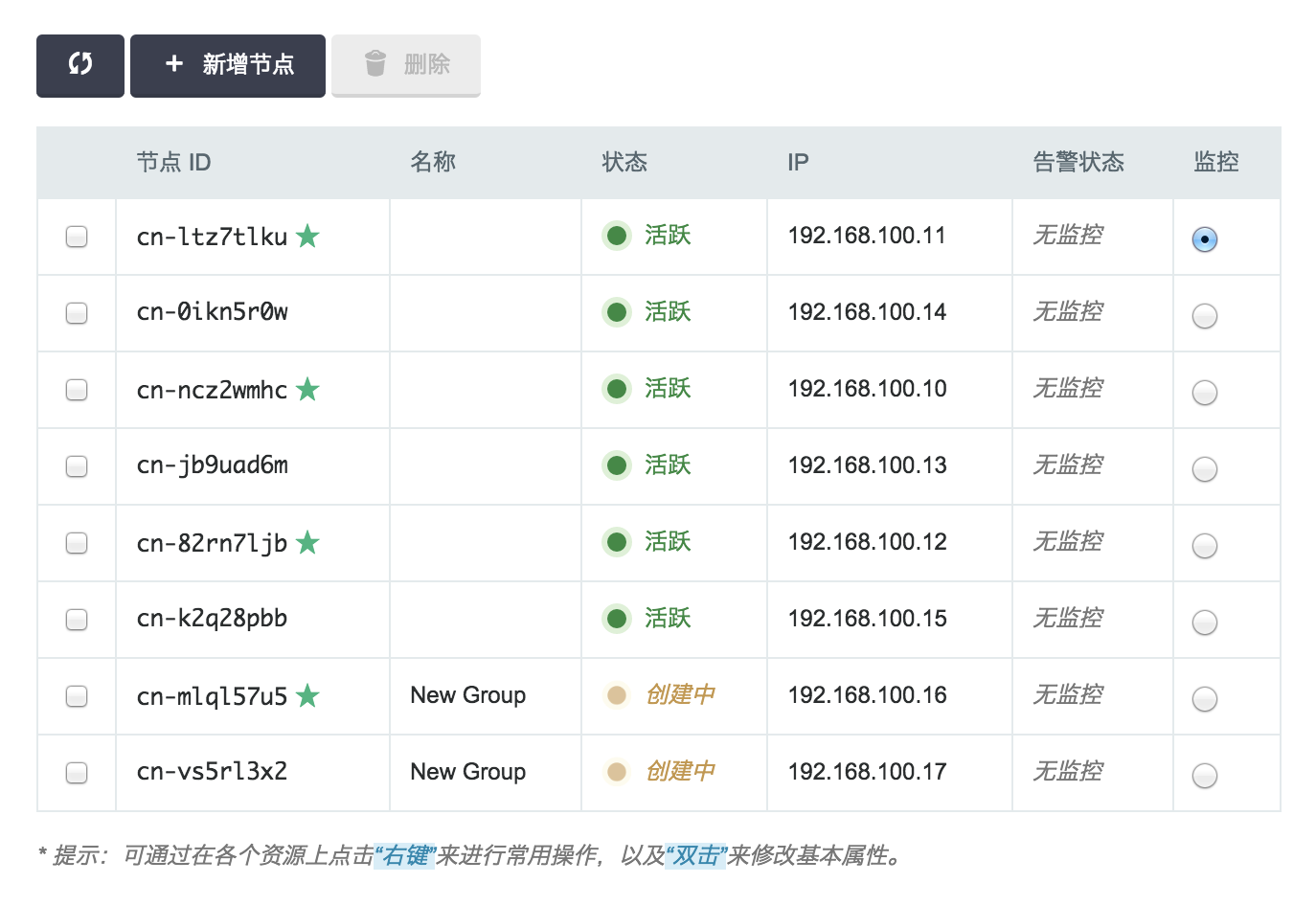
下图为扩容之后的节点列表。
2)增加集群从节点
Redis 集群服务每个主节点可以支持多个从节点。当读的能力不足时,您可以通过增加缓存从节点来提升读性能。 如图所示,我们在原有集群基础上新增一个从节点,并在创建时为新节点指定 IP,这个新增节点数 (replicate) 是针对于每个主节点而言, 因此该示例中总共要创建 4 个从节点(每主一个)。

下图为扩容之后的节点列表。
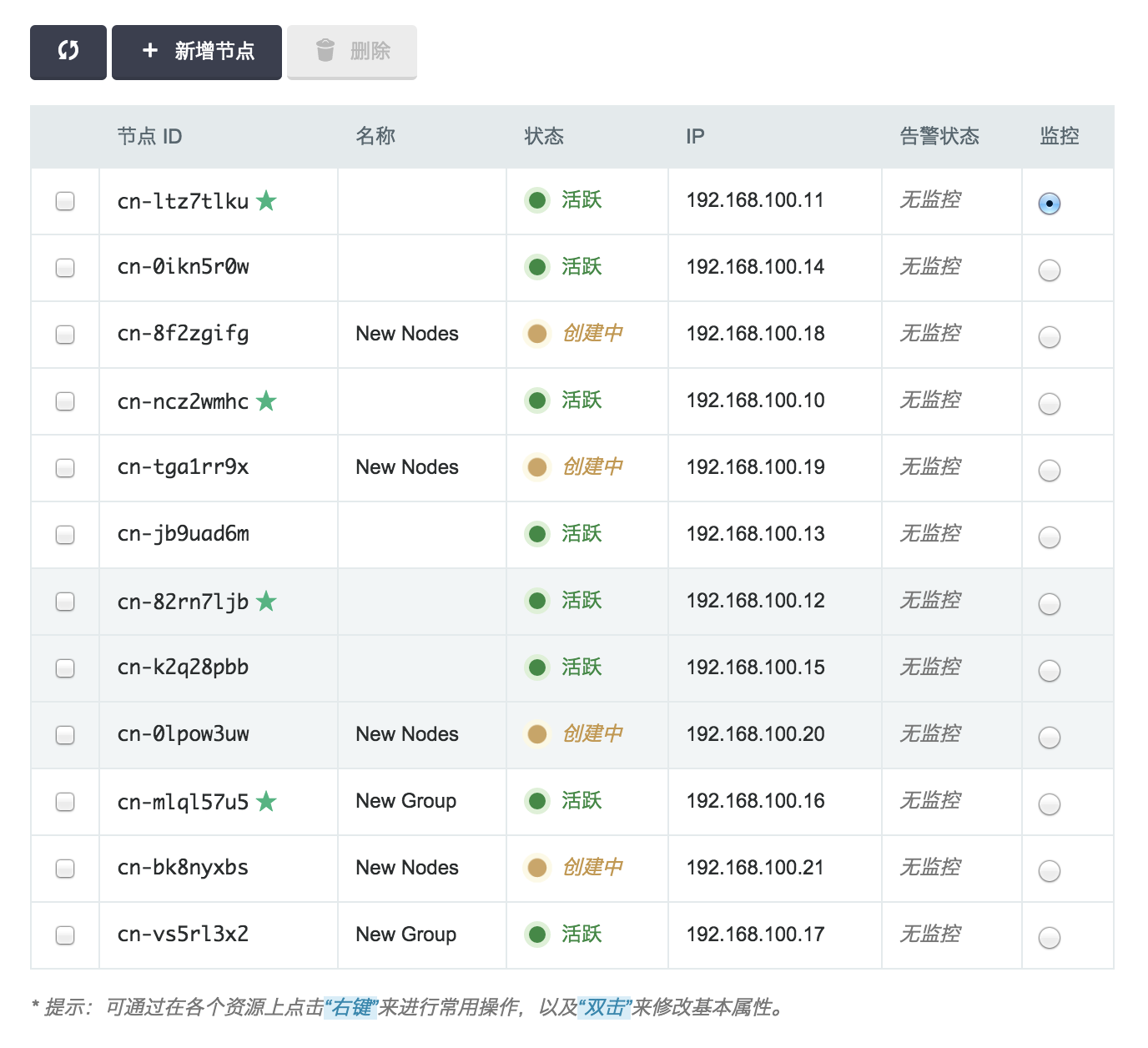
3)删除集群分片 (shard)
如果写服务能力或容量过剩,也可以删除多余的节点组,即删除主节点和它的所有从节点,删除的过程中系统会自动迁移数据到其它节点中,因此时间会稍长一点。
4)删除集群从节点
如果读服务能力过剩,您也可以删除多余的从节点。删除的时候需要从每个主节点下选择同样数目的从节点,从而保证整个集群不会是一个“畸形”。
5)增加缓存容量
当缓存容量不足时,您可以通过纵向扩容来提升缓存容量,右键点击缓存,选择扩容。 如下图所示,我们可以将原有缓存服务的容量从 1 GB 提升到 2 GB。
注解 存储容量只能扩容,不支持减少存储容量。在线扩容期间,缓存服务会被重启。

迁移
迁移数据既包括 Redis standalone 之间也包括从 Redis Standalone 到 Redis Cluster。
1)从 Redis standalone 迁移数据到 Redis cluster
Redis 3.x 提供了一个从 Redis standalone (包括旧版本 2.8.17) 迁移数据到 Redis cluster 的工具 redis-trib.rb, 请 下载 Redis 3.x, 解压后进入 Redis src目录, 执行以下命令 (假设 Redis standalone 的主节点 IP 为 192.168.100.11,端口为 6379, Redis cluster 其中一个 节点的 IP 为 192.168.100.20, 端口为 6379。
./redis-trib.rb import --from 192.168.100.11:6379 192.168.100.20:6379
注解 在做迁移之前建议对原 Redis standalone 做备份,因为上述操作是对数据进行迁移而不是拷贝。
2)从 Redis 2.8.17 迁移数据到 Redis 3.0.5
青云QingCloud Redis 服务也支持从旧版本 Redis standalone 迁移数据到新版本 Redis standalone, 具体操作参见 迁移, 您也可以用slaveof-host的方式同步数据,详情请见 slaveof-host 迁移。
升级
目前升级是通过迁移数据实现的,详细操作见上述 迁移部分 。
备份
Redis 集群由于是多节点分片且支持 HA,因此目前不支持备份功能,如果有需要用户需自行备份数据。
监控
Redis 集群的监控提供 Redis standalone 完全一样的监控信息,详情请见 监控。
图形化操作
青云QingCloud 提供了集群的图形化展示,方便用户更直观的查看集群状态和进行各项操作。部分截图如下:


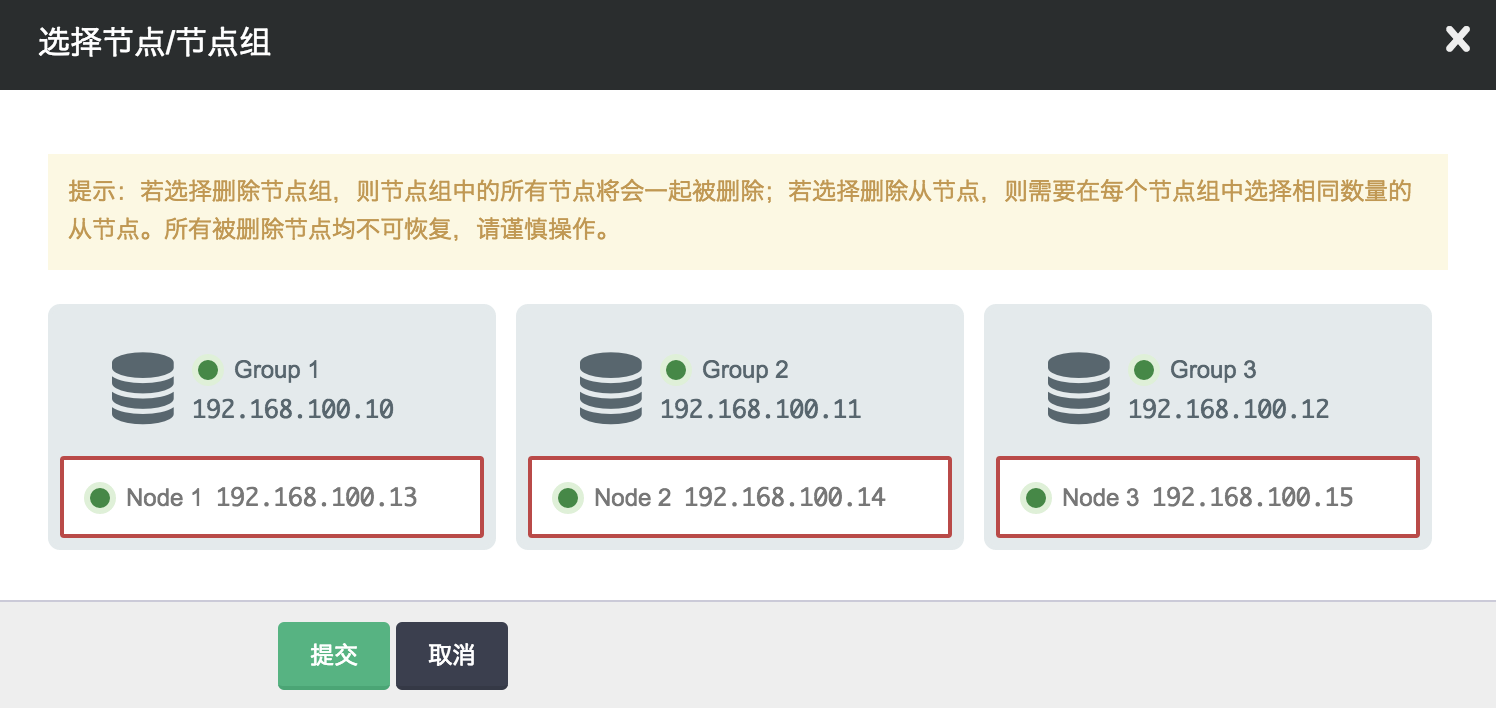
用户可以在图形中进行以下操作:
- 查看节点的监控信息
- 查看节点的基本信息
- 绑定节点的监控告警策略,并查看监控告警历史
- 添加、删除从节点
- 添加、删除节点组